
선형 자료 구조란?
선형 자료 구조란 요소가 일렬로 나열되어 있는 자료 구조를 말합니다.
연결 리스트(Linked List)
각 요소(노드)가 메모리상에 연속적으로 배치되지 않고, 개별적으로 분산되어 저장되며, 각 노드가 다음 노드에 대한 참조를 포함하는 구조입니다. 연결 리스트는 배열과 다르게, 삽입, 삭제가 용이하고, 크기가 가변적이라는 장점이 있습니다.
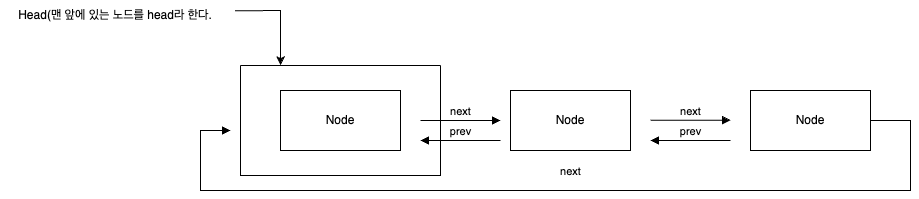
연결 리스트의 구조
연결 리스트의 기본 단위는 노드(Node)입니다. 각 노드는 다음과 같은 두 가지 구성 요소를 가집니다.
데이터(Date): 노드가 저장하는 값
포인터(Pointer): 다음 노드를 가리키는 참조
그래서 연결 리스트는 이 노드들이 연결된 형태로 구성되며, 각 노드는 다음 노드에 대한 참조를 가지고 있어 리스트를 순차적으로 탐색할 수 있습니다.
연결 리스트의 종류
1. 단일 연결 리스트(Singly Linked List)
각 노드가 다음 노드에 대한 참조만을 가지는 가장 단순한 형태의 연결 리스트입니다. 마지막 노드의 참조는 null을 가리키며, 이를 통해 리스트의 끝을 알 수 있습니다.
장점: 구현이 간단하고, 메모리 사용량이 적음
단점: 단방향이기 때문에 리스트를 역순으로 탐색할 수 없음

자바로 보는 코드 예시
// Node 클래스 정의
class Node {
int data; // 노드가 저장하는 데이터
Node next; // 다음 노드를 가리키는 참조 변수
// 생성자: 데이터 값을 받아서 노드를 생성
Node(int data) {
this.data = data;
this.next = null; // 새로 생성된 노드는 다음 노드를 가리키지 않음
}
}
// SinglyLinkedList 클래스 정의
class SinglyLinkedList {
private Node head; // 리스트의 시작점을 가리키는 head 노드
// 리스트에 새 노드를 추가하는 메서드
void add(int data) {
Node newNode = new Node(data); // 새 노드 생성
if (head == null) { // 리스트가 비어있다면, 새 노드를 head로 설정
head = newNode;
} else {
Node current = head;
while (current.next != null) { // 리스트의 끝까지 이동
current = current.next;
}
current.next = newNode; // 마지막 노드의 next를 새 노드로 설정
}
}
// 리스트의 모든 요소를 출력하는 메서드
void printList() {
Node current = head;
while (current != null) {
System.out.print(current.data + " ");
current = current.next;
}
System.out.println();
}
}
// 메인 클래스
public class Main {
public static void main(String[] args) {
SinglyLinkedList list = new SinglyLinkedList();
list.add(10); // 노드 추가
list.add(20);
list.add(30);
list.printList(); // 출력: 10 20 30
}
}
2. 이중 연결 리스트(Doubly Linked List)
각 노드가 이전 노드와 다음 노드에 대한 두 개의 참조를 가집니다. 그래서 리스트의 앞, 뒤로 탐색이 가능하며, 노드 삭제 시 더 효율적입니다.
장점: 양방향 탐색이 가능하고, 삭제나 삽입 시 인접 노드의 참조를 손쉽게 변경할 수 있음
단점: 단일 연결 리스트에 비해 메모리 사용량이 많고, 구현이 복잡함.
// Node 클래스 정의
class Node {
int data; // 노드에 저장할 데이터
Node prev; // 이전 노드를 가리키는 참조 변수
Node next; // 다음 노드를 가리키는 참조 변수
// 생성자: 데이터 값을 받아서 노드를 생성
Node(int data) {
this.data = data;
this.prev = null;
this.next = null;
}
}
// DoublyLinkedList 클래스 정의
class DoublyLinkedList {
private Node head; // 리스트의 시작점을 가리키는 head 노드
// 리스트에 새 노드를 추가하는 메서드 (맨 뒤에 추가)
void add(int data) {
Node newNode = new Node(data);
if (head == null) { // 리스트가 비어있다면, 새 노드를 head로 설정
head = newNode;
return;
}
Node current = head;
while (current.next != null) { // 리스트의 끝까지 이동
current = current.next;
}
current.next = newNode; // 마지막 노드의 next를 새 노드로 설정
newNode.prev = current; // 새 노드의 prev를 기존의 마지막 노드로 설정
}
// 리스트의 모든 요소를 앞에서 뒤로 출력하는 메서드
void printListForward() {
Node current = head;
System.out.print("Forward: ");
while (current != null) {
System.out.print(current.data + " ");
current = current.next;
}
System.out.println();
}
// 리스트의 모든 요소를 뒤에서 앞으로 출력하는 메서드
void printListBackward() {
if (head == null) return;
// 리스트의 끝까지 이동
Node current = head;
while (current.next != null) {
current = current.next;
}
System.out.print("Backward: ");
// 리스트의 끝에서부터 앞쪽으로 이동하며 출력
while (current != null) {
System.out.print(current.data + " ");
current = current.prev;
}
System.out.println();
}
}
// 메인 클래스
public class Main {
public static void main(String[] args) {
DoublyLinkedList list = new DoublyLinkedList();
// 노드 추가
list.add(10);
list.add(20);
list.add(30);
// 리스트의 요소를 앞에서부터 출력
list.printListForward(); // 출력: Forward: 10 20 30
// 리스트의 요소를 뒤에서부터 출력
list.printListBackward(); // 출력: Backward: 30 20 10
}
}
3. 원형 연결 리스트(Circular Linked List)
마지막 노드가 첫 번째 노드를 가리켜 원형 형태로 연결된 구조입니다. 헤드에서부터 끝까지 한 바퀴를 순환할 수 있으며, 큐 같은 자료 구조를 구현할 때 유용합니다.
장점: 리스트의 어느 위치에서 시작하더라도 순환하면서 모든 노드를 탐색할 수 있음.
단점: 무한 루프에 빠질 가능성이 있으며, 종료 조건을 명시적으로 설정해야 함.
// Node 클래스 정의
class Node {
int data; // 노드에 저장할 데이터
Node next; // 다음 노드를 가리키는 참조 변수
// 생성자: 데이터 값을 받아서 노드를 생성
Node(int data) {
this.data = data;
this.next = null; // 다음 노드를 가리키는 참조를 null로 초기화
}
}
// CircularLinkedList 클래스 정의
class CircularLinkedList {
private Node head; // 리스트의 시작점을 가리키는 head 노드
private Node tail; // 리스트의 끝을 가리키는 tail 노드
// 리스트에 새 노드를 추가하는 메서드
void add(int data) {
Node newNode = new Node(data);
if (head == null) { // 리스트가 비어있다면, head와 tail을 모두 새 노드로 설정
head = newNode;
tail = newNode;
tail.next = head; // tail의 next가 head를 가리키도록 설정하여 원형 구조 완성
} else {
tail.next = newNode; // 기존 tail의 next를 새 노드로 설정
tail = newNode; // tail을 새 노드로 변경
tail.next = head; // tail의 next가 다시 head를 가리키도록 설정
}
}
// 리스트의 모든 요소를 출력하는 메서드
void printList() {
if (head == null) return; // 리스트가 비어있으면 출력하지 않음
Node current = head;
do {
System.out.print(current.data + " ");
current = current.next;
} while (current != head); // 다시 head로 돌아올 때까지 반복
System.out.println();
}
}
// 메인 클래스
public class Main {
public static void main(String[] args) {
CircularLinkedList list = new CircularLinkedList();
// 노드 추가
list.add(10);
list.add(20);
list.add(30);
// 리스트의 요소 출력
list.printList(); // 출력: 10 20 30
}
}연결 리스트의 주요 연산
삽입(Insertion)
- 리스트의 특정 위치에 새로운 노드를 추가하는 연산.
- 배열의 경우 삽입 시 해당 위치 뒤의 요소들을 모두 이동시켜야 하지만, 연결 리스트는 포인터만 변경하면 되므로 효율적입니다.
- 시간 복잡도: O(1) (리스트의 맨 앞 또는 맨 뒤에 삽입할 경우), O(n) (특정 위치에 삽입할 경우).
삭제(Deletion)
- 특정 노드를 리스트에서 제거하는 연산.
- 삭제할 노드의 참조를 끊고, 이전 노드의 포인터를 다음 노드를 가리키도록 변경.
- 시간 복잡도: O(1) (맨 앞 또는 맨 뒤 노드 삭제 시), O(n) (특정 위치의 노드 삭제 시).
탐색(Search)
- 리스트에서 특정 값을 가지는 노드를 찾는 연산.
- 각 노드를 순차적으로 탐색해야 하므로, 배열의 인덱스 접근에 비해 비효율적.
- 시간 복잡도: O(n) (최악의 경우).
반복(Traversal)
- 리스트의 모든 노드를 순차적으로 방문하여 값을 출력하거나 특정 연산을 수행.
- 시간 복잡도: O(n).
종합적으로 보는 연결 리스트의 장단점
장점
- 크기가 가변적이기 때문에 요소를 삽입하거나 삭제할 때 메모리의 효율적인 사용이 가능.
- 특정 위치에서의 삽입, 삭제가 배열보다 효율적 (O(1)).
단점
- 인덱스를 통한 접근이 불가능하여 임의 위치에 접근할 때 비효율적 (O(n)).
- 포인터를 저장하는 추가 메모리 공간이 필요.
- 포인터를 잘못 설정할 경우 메모리 누수, 무한 루프 등의 오류 발생 가능.
연결 리스트는 어디에 활용하나요?
- 스택(Stack) 및 큐(Queue) 자료 구조 구현.
- 그래프 및 트리와 같은 복잡한 자료 구조 구현.
- 메모리 관리: 가비지 컬렉션 알고리즘이나 메모리 풀에서의 사용.
-가비지 컬렉션(Garbage Collection, GC): 알고리즘은 프로그래밍 언어의 메모리 관리를 자동으로 수행하는 기능으로, 프로그램 실행 중에 더 이상 사용되지 않거나 참조되지 않는 메모리(객체)를 찾아 해제함으로써 메모리 누수를 방지하고 메모리 사용 효율을 높여준다.
-메모리 풀(Memory pool):
메모리 할당 및 해제의 성능을 최적화하기 위해 미리 메모리 블록을 할당해 두고, 필요할 때 이를 재사용하는 메모리 관리 기법입니다. 메모리 풀을 사용하면 동적 메모리 할당과 해제 시 발생하는 비용(예: 메모리 단편화, 성능 저하)을 줄이고, 메모리의 사용 효율을 높일 수 있다.
배열(Array)
(여기서는 정적 배열을 기반으로 설명합니다.)고정된 크기의 연속된 메모리 공간에 저장된 데이터 집합으로, 배열의 크기는 선언 시에 결정되고 이후에는 변경할 수 없습니다. 배열의 각 요소는 인덱스(index)를 통해 접근할 수 있으며, 이러한 접근 방식은 크게 두 가지로 구분됩니다: 랜덤 접근(random access)과 순차 접근(sequential access)입니다.
1. 랜덤 접근 (Random Access)
랜덤 접근은 배열의 임의의 인덱스에 직접 접근하는 방식입니다. 이 접근 방식은 배열의 특징인 인덱스를 통한 빠른 접근 속도 때문에 가능하며, 정적 배열의 경우 O(1)의 시간 복잡도를 가집니다.
랜덤 접근의 특징
- 빠른 접근 속도: 인덱스를 사용하여 배열의 특정 위치에 있는 요소에 즉시 접근할 수 있습니다. 예를 들어, 배열 arr의 다섯 번째 요소에 접근하려면 arr[4]라고 작성하면 되며, 배열의 크기와 관계없이 즉시 해당 요소에 접근할 수 있습니다.
- 연속적인 메모리 할당: 배열의 요소들은 메모리에서 연속적으로 할당되므로, 특정 인덱스에 대한 주소를 직접 계산하여 접근할 수 있습니다. 배열의 첫 번째 요소의 메모리 주소를 base_address라고 하면, n번째 요소의 주소는 base_address + (n * element_size)로 쉽게 계산할 수 있습니다.
- 효율적: 랜덤 접근은 데이터 검색이 빠르고 효율적이며, 특정 요소를 수정하거나 확인할 때 유리합니다.
public class RandomAccessExample {
public static void main(String[] args) {
int[] arr = {10, 20, 30, 40, 50};
// 특정 인덱스의 요소에 접근 (랜덤 접근)
int value = arr[2]; // arr의 세 번째 요소에 접근 (index 2)
System.out.println("세 번째 요소: " + value); // 출력: 세 번째 요소: 30
// 특정 인덱스의 요소를 수정
arr[4] = 100; // arr의 다섯 번째 요소를 100으로 변경
System.out.println("변경된 다섯 번째 요소: " + arr[4]); // 출력: 변경된 다섯 번째 요소: 100
}
}
2. 순차 접근 (Sequential Access)
순차 접근은 배열의 요소에 처음부터 차례대로 접근하는 방식입니다. 특정 위치에서 바로 접근하는 랜덤 접근과 달리, 순차 접근은 배열의 첫 번째 요소부터 차례대로 이동하면서 접근합니다.
순차 접근의 특징
- 첫 번째 요소부터 차례대로 접근: 배열의 처음부터 순차적으로 다음 요소로 이동하면서 접근합니다. 예를 들어, 배열의 모든 요소를 출력하거나 특정 조건에 맞는 요소를 찾는 경우에 사용됩니다.
- 배열 전체 순회에 용이: 순차 접근은 배열의 모든 요소를 확인해야 할 때 적합합니다. 예를 들어, 배열 내의 최대값을 찾거나 모든 요소를 더하는 경우 순차 접근이 필요합니다.
- O(n) 시간 복잡도: 배열의 길이가 n일 때, 순차 접근을 통해 배열의 모든 요소를 확인하는 데는 O(n) 시간이 걸립니다.
public class SequentialAccessExample {
public static void main(String[] args) {
int[] arr = {5, 10, 15, 20, 25};
int sum = 0;
// 순차 접근을 통해 배열의 모든 요소를 더함
for (int i = 0; i < arr.length; i++) {
sum += arr[i]; // 각 요소를 더함
}
System.out.println("배열 요소의 합: " + sum); // 출력: 배열 요소의 합: 75
}
}
비열과 연결 리스트 비교
배열은 상자를 순서대로 나열한 데이터 구조이며 몇 번째 상자인지만 알면 해당 상자의 요소를 끄집어낼 수 있습니다. 연결 리스트는 상자를 선으로 연결한 형태의 데이터 구조이며, 상자 안의 요소를 알기 위해서는 하나씩 상자 내부를 확인해봐야 한다는 점이 다릅니다.
배열: 랜덤 접근이 가능하다. O(1)
연결 리스트: 랜덤 접근이 불가능하다. O(n)
배열 (Array)
• 접근 방법: 인덱스를 사용하여 랜덤 접근이 가능, O(1)의 시간 복잡도로 요소에 접근.
• 메모리: 연속된 메모리 공간에 저장되며, 배열의 크기는 선언 시에 고정됨.
• 장점:
• 빠른 데이터 접근 (랜덤 접근).
• 메모리 효율성이 높음 (메모리 할당과 해제가 필요 없음).
• 단점:
• 크기가 고정되어 있어, 크기를 변경하려면 새 배열을 생성하고 복사해야 함.
• 중간에 요소를 삽입하거나 삭제할 때 비효율적 (O(n)).
연결 리스트 (Linked List)
• 접근 방법: 순차적으로 접근해야 하며, 특정 요소에 접근하는 데 O(n)의 시간 복잡도 소요.
• 메모리: 노드들이 메모리의 불연속적인 위치에 저장되며, 각 노드가 다음 노드를 가리키는 포인터를 가짐.
• 장점:
• 크기를 동적으로 조절 가능 (노드를 추가하거나 삭제하는 데 유연함).
• 중간에 요소를 삽입하거나 삭제할 때 효율적 (O(1), 노드를 찾아야 할 경우 O(n)).
• 단점:
• 메모리 사용량이 더 많음 (포인터를 저장해야 하므로).
• 랜덤 접근이 불가능하여 데이터 접근 속도가 느림.
백터(Vector)
벡터(Vector)는 동적 배열을 기반으로 하는 자료 구조로, 배열과 유사하게 데이터를 순차적으로 저장하지만 몇 가지 중요한 차이점과 추가적인 기능을 제공합니다. 벡터는 주로 프로그래밍 언어의 표준 라이브러리에서 제공되며, Java의 ArrayList, C++의 std::vector 등이 그 예입니다.
정의 및 동작 원리
벡터는 데이터 요소를 연속적으로 저장하는 자료 구조로, 크기가 동적으로 조정됩니다. 벡터의 동작 원리는 다음과 같습니다:
1. 초기화:
• 벡터는 일반적으로 초기 용량을 지정할 수 있으며, 이 용량만큼의 메모리를 할당받습니다. 이 초기 용량은 벡터에 저장할 수 있는 요소의 수를 나타냅니다.
2. 추가:
• 요소를 추가할 때, 현재 용량이 가득 찼다면 벡터는 새로운 배열을 생성하고 기존 데이터를 복사합니다. 일반적으로 새 배열의 크기는 기존 배열의 두 배로 설정됩니다. 이 과정에서 성능이 저하될 수 있지만, 추가적인 공간이 확보되므로 이후의 추가 연산은 더 효율적으로 수행될 수 있습니다.
3. 삭제:
• 요소를 삭제할 때는 삭제된 요소의 뒤에 있는 모든 요소를 한 칸씩 앞으로 이동시켜야 하므로 O(n)의 시간 복잡도가 발생합니다. 이 과정은 요소가 삭제되는 위치에 따라 성능에 영향을 미칠 수 있습니다.
4. 접근:
• 벡터는 인덱스를 사용하여 데이터를 저장하므로 랜덤 접근이 가능하며, 특정 인덱스의 요소에 O(1)의 시간 복잡도로 접근할 수 있습니다.
주요 특징
1. 동적 크기:
• 사용자가 필요에 따라 요소를 추가하거나 삭제할 수 있으므로 벡터의 크기가 유동적입니다. 이로 인해 고정된 크기의 배열보다 유연하게 데이터를 처리할 수 있습니다.
2. 연속적인 메모리:
• 벡터는 내부적으로 연속된 메모리 블록에 저장되므로, 데이터에 빠르게 접근할 수 있습니다. 이는 메모리 캐시의 효율성을 높이는 데 기여합니다.
3. 풍부한 메서드:
• 벡터는 다양한 메서드를 제공하여 요소를 추가, 삭제, 검색하는 작업을 간편하게 수행할 수 있도록 합니다. 예를 들어, Java의 ArrayList에서는 add(), remove(), get(), size() 등의 메서드를 제공합니다.
자바로 보는 예시 코드
import java.util.ArrayList;
public class VectorExample {
public static void main(String[] args) {
// 벡터 생성
ArrayList<Integer> vector = new ArrayList<>();
// 요소 추가
vector.add(10); // 인덱스 0
vector.add(20); // 인덱스 1
vector.add(30); // 인덱스 2
System.out.println("벡터의 요소: " + vector); // 출력: [10, 20, 30]
// 요소 삭제
vector.remove(1); // 인덱스 1의 요소(20) 삭제
System.out.println("삭제 후 요소: " + vector); // 출력: [10, 30]
// 특정 인덱스의 요소에 접근
int value = vector.get(0);
System.out.println("첫 번째 요소: " + value); // 출력: 10
// 벡터의 크기 확인
System.out.println("벡터의 크기: " + vector.size()); // 출력: 2
// 모든 요소 출력
for (Integer num : vector) {
System.out.println("요소: " + num);
}
}
}
장점
• 동적 크기 조정: 필요에 따라 배열의 크기를 자동으로 조정하므로, 데이터의 양이 불확실할 때 유용합니다.
• 랜덤 접근 가능: 배열처럼 인덱스를 사용하여 요소에 빠르게 접근할 수 있어 성능이 뛰어납니다.
• 유연한 데이터 처리: 다양한 메서드를 제공하여 데이터 삽입, 삭제, 검색 등을 간편하게 처리할 수 있습니다.
단점
• 메모리 오버헤드: 벡터는 내부적으로 동적 메모리를 할당하고 관리해야 하므로 메모리 오버헤드가 발생할 수 있습니다. 또한, 크기를 조정할 때마다 새로운 메모리 블록을 할당하고 데이터를 복사해야 하므로, 추가 작업에서 성능 저하가 발생할 수 있습니다.
• 비효율적인 삽입/삭제: 중간에 요소를 삽입하거나 삭제할 경우, 모든 후속 요소를 이동해야 하므로 O(n)의 시간 복잡도가 소요되어 비효율적일 수 있습니다.
-메모리 오버헤드(Memory Overhead): 프로그램이 실행될 때, 실제로 필요한 메모리 양 외에 추가로 사용되는 메모리 공간을 의미
'Computer Science' 카테고리의 다른 글
| 자료 구조 - 복잡도 (0) | 2024.09.21 |
|---|---|
| 트랜잭션과 무결성 (0) | 2024.09.14 |
| CPU 스케줄링 알고리즘 (7) | 2024.09.07 |
| 메모리(Memory) (6) | 2024.09.01 |
| Stack, Method, Heap 메모리 (0) | 2024.08.11 |