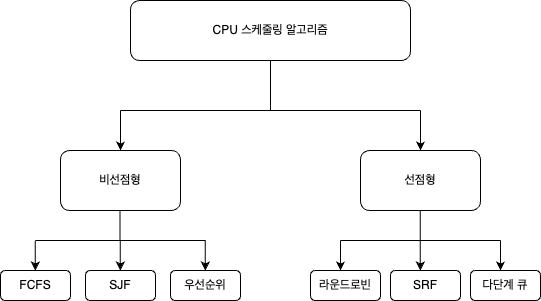
CPU 스케줄링 알고리즘은 CPU의 작업 처리 순서를 결정하는 방법으로, 여러 프로세스가 CPU를 공유해야 할 때 효율적으로 CPU 자원을 배분하는 데 사용됩니다. 각 알고리즘은 서로 다른 방식으로 CPU를 할당하여, 주로 처리 시간, 우선순위, 대기 시간 등을 고려한다.

그래서 프로그램이 실행될 때는 CPU 스케줄링 알고리즘이 어떤 프로그램에 CPU 소유권을 줄 것인지 결정한다. 이 알고리즘은 CPU 이용률은 높게, 주어진 시간에 많은 일을 하게, 준비 큐(readt queue)에 있는 프로세스느 적게, 응답 시간은 짧게 설정하는 것을 목표로 한다.
-개념 참고-
https://www.javatpoint.com/cpu-scheduling-algorithms-in-operating-systems
CPU Scheduling Algorithms in Operating Systems - javatpoint
CPU Scheduling Algorithms in Operating Systems with OS Tutorial, Types of OS, Process Management, Attributes of a Process, CPU Scheduling, FCFS with overhead, FCFS Scheduling etc.
www.javatpoint.com
비선점형 스케줄링(Non - Preemptive Scheduling)
한 번 CPU를 할당받은 프로세스가 자발적으로 종료하거나, 입출력(I/O) 요청 등의 이유로 CPU를 반환할 때까지 다른 프로세스가 CPU를 차지할 수 없는 방식이다. 다시 말해, 현재 실행 중인 프로세스가 CPU 사용을 스스로 끝나기 전까지는 다른 프로세스가 그 자원을 사용할 수 없다는 특징이 있다.
비선점형 특징으로는
- 문맥 전환 최소화: 비선점형 방식은 선점형 방식과 달리, 실행 중인 프로세스를 강제로 중단하지 않으므로 문맥 전환(Context Swithching)이 적게 발생한다. 문맥 전환은 CPU 자원을 사용하고, 시스템에 부하를 줄 수 있기 때문에, 이를 줄임으로써 오버헤드를 최소화 할 수 있다
-문맥 전환: 다른 프로세스를 실행하기 위해 상태 정보를 저장하고 복구하는 과정
-오버헤드: 프로세스 실행 외에 발생하는 시스템의 추가적인 작업이나 자원 소모를 의미
하지만 이에 대해 단점이 있으니...
긴 실행 시간을 가진 프로세스가 있을 경우, 다른 프로세스가 오랫동안 기다려야 할 수 있다.
주요 알고리즘
FCFS(First -Come, First-Served)
가장 단순한 CPU 스케줄링 알고리즘 중 하나로, "선착순" 방식으로 프로세스를 처리한다. 즉, 먼저 도착한 프로세스가 먼저 CPU를 할당받고, 그 프로세스가 끝날 때까지 다른 프로세스는 기다려야 한다.
동작 방식
- 준비 큐: 프로세스는 도착하는 순서대로 준비 큐에 들어갑니다.
- 실행 순서: 첫 번째로 도착한 프로세스가 먼저 실행되며, CPU를 할당받은 후 작업을 완료할 때까지 CPU를 독점적으로 사용합니다.
- 처리 완료: 첫 번째 프로세스가 끝나면 두 번째로 도착한 프로세스가 CPU를 할당받는 식으로 순차적으로 처리됩니다.
큐(Queue): FIFO(First In, First Out) 방식으로 데이터를 처리하는 자료 구조
준비 큐(Ready Queue): 실행 준비가 완료된 프로세스들이 대기하는 큐
작동 예시
- 프로세스 도착 시나리오: 3개의 프로세스 P1, P2, P3가 다음과 같은 시간에 도착하고, 각각의 실행 시간이 다를 경우를 가정합니다.
- P1: 도착 시간 0, 실행 시간 5
- P2: 도착 시간 2, 실행 시간 2
- P3: 도착 시간 4, 실행 시간 1
- P1 실행: P1이 먼저 도착했으므로 CPU를 할당받아 0초부터 5초까지 실행합니다.
- P2 대기: P2는 2초에 도착했으나 P1이 끝날 때까지 기다립니다.
- P2 실행: P1이 5초에 끝나면 P2가 5초부터 7초까지 실행됩니다.
- P3 대기: P3는 4초에 도착했으나 P2가 끝날 때까지 기다립니다.
- P3 실행: P2가 끝난 후 P3가 7초부터 8초까지 실행됩니다.
0 5 7 8
|-------|-------|--------|
P1 P2 P3
FCFS의 주요 특징
- 비선점형: 프로세스가 한 번 CPU를 할당받으면 작업을 마칠 때까지 CPU를 양보하지 않습니다. 다른 프로세스는 대기해야 합니다.
- 간단한 구현: FCFS는 FIFO(First-In, First-Out) 방식의 큐 자료구조를 이용하여 구현이 간단합니다.
- 공평성: 먼저 도착한 프로세스가 먼저 처리되기 때문에 모든 프로세스가 도착 순서대로 공평하게 CPU를 할당받습니다. 하지만 이것이 반드시 효율적이라는 의미는 아닙니다.
FCFS의 장점
- 구현이 쉬움: 다른 복잡한 스케줄링 알고리즘에 비해 구현이 매우 간단합니다.
- 공정성 보장: 먼저 도착한 순서대로 CPU를 할당받기 때문에 공정성이 보장됩니다.
- 처리 오버헤드가 적음: 선점형 스케줄링과 달리 문맥 전환(Context Switching)이 거의 발생하지 않기 때문에 오버헤드가 적습니다.
FCFS의 단점
- Convoy Effect (무리 효과)
실행 시간이 긴 프로세스가 먼저 도착하면, 그 뒤에 도착한 실행 시간이 짧은 프로세스들이 그 긴 프로세스가 끝날 때까지 기다려야 하는 상황이 발생할 수 있습니다. 이를 Convoy Effect라고 하며, 시스템의 효율성을 저하시킬 수 있습니다.- 예시: P1의 실행 시간이 20초, P2가 1초라면, P2는 P1이 끝날 때까지 기다려야 하므로 전체 시스템 응답 시간이 느려질 수 있습니다.
- 평균 대기 시간이 길어질 수 있음
FCFS에서는 실행 시간이 긴 프로세스가 먼저 도착할 경우, 그 뒤의 모든 프로세스가 길게 대기할 수 있습니다. 이는 대기 시간이 비효율적으로 길어지는 결과를 초래할 수 있습니다. - 비선점형 특성의 한계
중요한 프로세스나 긴급한 작업이 도착해도, 현재 실행 중인 프로세스가 끝날 때까지 기다려야 하는 단점이 있습니다. 따라서 실시간 시스템이나 중요한 작업을 처리할 때는 적합하지 않습니다.
FCFS를 사용할 때 적합한 경우
- 시스템이 간단하거나, 응답 시간보다는 작업이 순차적으로 처리되는 것이 더 중요한 경우에 적합합니다.
- 실시간 요구가 없고, 짧은 작업과 긴 작업의 혼합이 많지 않은 시스템에 적합합니다.
SJF (Shortest Job First)
각 프로세스의 실행 시간을 기준으로 가장 짧은 작업부터 먼저 처리하는 방식입니다. 이 알고리즘의 주요 목표는 평균 대기 시간을 최소화하는 것으로, 실행 시간이 짧은 작업을 먼저 처리함으로써 시스템 성능을 최적화하려는 것입니다.
SJF의 주요 개념
- 실행 시간(서비스 시간): 각 프로세스가 CPU에서 실행되는 데 필요한 시간입니다. SJF는 이 실행 시간을 기준으로 가장 짧은 작업을 우선적으로 처리합니다.
- 대기 시간: 프로세스가 CPU를 할당받기 전까지 대기하는 시간입니다. SJF는 실행 시간이 짧은 작업을 먼저 처리하기 때문에 대기 시간을 줄이는 데 유리합니다.
- 평균 대기 시간: 모든 프로세스의 대기 시간의 평균을 말합니다. SJF의 주된 장점은 평균 대기 시간을 최소화할 수 있다는 점입니다.
SJF (Non-Preemptive SJF)
SJF 스캐줄링에서는 한 번 CPU를 할당받은 프로세스는 자발적으로 종료될 때까지 CPU를 독점적으로 사용합니다. 즉, CPU가 할당된 프로세스는 중간에 다른 프로세스에 의해 끼어들지 않고, 끝날 때까지 실행됩니다.
동작 원리:
- 프로세스가 CPU를 요청하면, 대기 중인 모든 프로세스의 실행 시간을 비교합니다.
- 실행 시간이 가장 짧은 프로세스에 CPU를 할당합니다.
- CPU가 할당된 프로세스는 완료될 때까지 실행되며, 다른 프로세스는 대기 상태로 남습니다.
예시:
- p1, p2, p3 세 개의 프로세스가 도착했다고 가정합니다.
- p1: 실행 시간 5ms, p2: 3ms, p3: 1ms
- 먼저 도착한 프로세스 p1가 CPU를 할당받습니다. 그러나 p2와 p3는 대기 중입니다. 이때, p3의 실행 시간이 가장 짧으므로 p1가 끝난 후에 p3가 실행됩니다. 마지막으로 p2가 실행됩니다.
장점:
- 단순성: 한 번 할당된 프로세스가 끝날 때까지 실행되므로 구현이 비교적 쉽습니다.
- 문맥 전환 비용 감소: CPU 할당이 자주 바뀌지 않기 때문에 문맥 전환이 발생하지 않아 오버헤드가 적습니다.
단점:
- 긴 대기 시간: 긴 작업이 먼저 실행되면 짧은 작업들이 오랫동안 대기해야 할 수 있습니다.
- Starvation(기아 현상): 만약 긴 작업이 계속 도착하면, 긴 작업들이 처리되기 전까지 짧은 작업들이 오랫동안 대기할 수 있습니다.
-Starvation(기아 현상): 특정 프로세스가 오랫동안 CPU나 다른 자원을 할당받지 못하고 계속해서 대기 상태에 빠지는 현상
Priority Scheduling(우선순위 스케줄링)
은 각 프로세스에 우선순위(priority)를 부여하고, 우선순위가 높은 프로세스에 CPU를 먼저 할당하는 스케줄링 알고리즘입니다. 프로세스의 우선순위는 숫자로 나타낼 수 있으며, 숫자가 낮을수록 우선순위가 높다고 할 수 있습니다(일반적으로 낮은 숫자가 높은 우선순위).
-우선순위 스케줄링 참고-
https://www.naukri.com/code360/library/non-preemptive-priority-based-scheduling
Non-Preemptive Priority Based Scheduling - Naukri Code 360
Introduction We know that various scheduling algorithms are used to assign resources to perform different tasks. One of these CPU algorithms is Priority based scheduling. As the name itself suggests, it is related to the priority of the task to be performe
www.naukri.com
우선순위 스케줄링 (Priority Scheduling)
- 현재 CPU를 사용 중인 프로세스가 완료될 때까지 CPU를 계속 사용합니다.
- 새로 도착한 프로세스의 우선순위가 더 높아도 기다려야 합니다.
- CPU가 비어 있을 때, 대기 중인 프로세스들 중에서 가장 높은 우선순위를 가진 프로세스가 CPU를 할당받습니다.
우선순위의 정의
우선 순위는 어떤 요소에 따라 정해졌나?
내부 우선순위
- 시간 제한
- 프로세스의 메모리 요구 사항
- 평균 I/O버스트와 평균 CPU 버스트의 비율입니다
-버스트: 프로세스가 CPU를 사용하는 시간
외부 우선순위
- 작업의 중요성
- 컴퓨터 사용에 할당된 자금의 양
- 해당 작업을 후원하는 부서 등
만 일 두 개 이상의 작업이 동일한 우선순위를 가지고 있는 경우는?
FCFS(선착순) 기준으로 실행됩니다. 그 중 먼저 도착한 프로세스가 먼저 CPU를 할당받습니다.
Priority Scheduling의 장점
- 중요한 작업 우선 처리: 높은 우선순위의 중요한 작업을 빠르게 처리할 수 있어 긴급한 작업에 적합합니다.
- 유연성: 우선순위를 동적으로 설정할 수 있어, 시스템 또는 사용자 요구에 맞춰 스케줄링 전략을 조정할 수 있습니다.
Priority Scheduling의 단점
- Starvation(기아 현상): 우선순위가 낮은 프로세스는 우선순위가 높은 프로세스들에 의해 CPU를 오랫동안 할당받지 못할 수 있습니다.
- 해결 방법: **에이징(Aging)**이라는 기법을 사용해 오랫동안 대기 중인 프로세스의 우선순위를 점진적으로 높이는 방법을 사용해 Starvation 문제를 해결할 수 있습니다.
- 우선순위 할당의 복잡성: 프로세스마다 적절한 우선순위를 설정하는 것이 어렵거나 부적절하게 설정될 경우, 시스템 성능이 저하될 수 있습니다.
Priority Scheduling의 응용
- 실시간 시스템: 중요한 작업을 우선적으로 처리하는 스케줄링이 필요할 때 유용합니다.
- 긴급한 작업이 많은 환경: 우선순위가 높은 작업이 빨리 처리되어야 하는 경우 적합합니다.
그래서 Priority Scheduling은 시스템 자원의 효율적 배분과 중요 작업의 우선 처리가 필요한 다양한 환경에서 적용될 수 있으며, 특히 긴급 작업 처리가 중요한 시스템에서 많이 사용됩니다.
선점형 스케줄링(Preemptive Scheduling)
현재 실행 중인 프로세스를 중단하고, 더 높은 우선순위를 가진 프로세스나 새로 도착한 프로세스에 CPU를 할당하는 스케줄링 방식입니다. 즉 이미 CPU를 할당받은 프로세스가 아직 완료되지 않았더라도, 더 중요한 작업이 있으면 CPU 제어권을 빼앗겨야 하는 방식입니다.
이 방식은 비선점형 스케줄링과 달리, 프로세스가 CPU를 독점하지 못하고 중간에 다른 프로세스에 의해 선점될 수 있기 때문에 동적이고 실시간적인 자원 배분에 유리합니다.
선점형 스케줄링의 동작 방식
- 새로운 프로세스 도착: 새로운 프로세스가 도착하면, 스케줄러는 현재 실행 중인 프로세스와 도착한 프로세스의 우선순위나 CPU 할당 기준을 비교합니다.
- 현재 프로세스 중단 가능: 새로운 프로세스가 더 높은 우선순위를 가지거나, 더 중요한 프로세스일 경우, 현재 실행 중인 프로세스를 중단하고 새로운 프로세스에 CPU를 할당합니다.
- 중단된 프로세스 재개: 중단된 프로세스는 나중에 다시 재개되어 작업을 마칩니다. 이 과정에서 문맥 전환(Context Switch)이 발생하게 됩니다.
라운드 로빈 스케줄링(Round Robin Scheduling)
각 프로세스에 고정된 시간(Time Quantum) 동안만 CPU를 할당하고, 그 시간이 지나면 다음 프로세스에 CPU를 할당하는 방식입니다. 모든 프로세스가 순서대로 돌아가며 공평하게 CPU를 사용하게 됩니다.
라운드 로빈 스케줄링은 선점형 스케줄링 방식의 대표적인 예로, 멀티테스킹 운영체제에서 많이 사용됩니다.이 방식은 FCFS(First-Come, First-Served) 스케줄링의 공평성을 유지하면서도, 각 프로세스가 일정 시간 이상 CPU를 독점하지 않도록 보장합니다.
라운드 로빈 스케줄링의 동작 방식
- 프로세스 대기열: 모든 프로세스는 큐(Queue)에 저장되며, 순서대로 CPU를 할당받습니다.
- 타임 퀀텀(Time Quantum): 각 프로세스는 일정한 시간(타임 퀀텀) 동안만 CPU를 사용할 수 있습니다.
- 시간 초과: 프로세스가 타임 퀀텀 내에 완료되지 않으면 중단되고, 큐의 마지막으로 이동하여 다시 대기합니다.
- 다시 할당: 그 다음 프로세스가 CPU를 할당받고, 순차적으로 반복됩니다.
라운드 로빈 스케줄링의 예시
프로세스 실행 시간 (Burst Time) 도착 시간
P1 5 0
P2 8 1
P3 6 2
P4 4 3
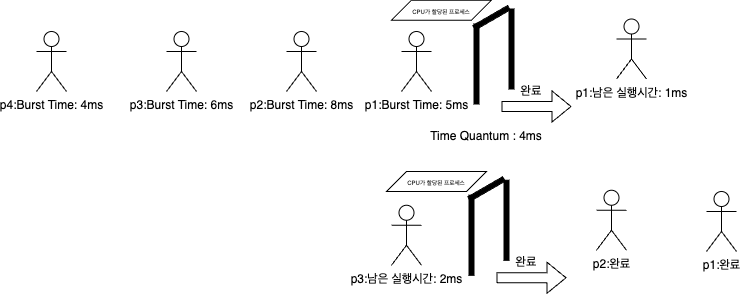
스케줄링 순서:
- P1 → P2 → P3 → P4 → P1 → P2 → P3
라운드 로빈 스케줄링의 특징
- 타임 퀀텀(Time Quantum):
- 타임 퀀텀이 짧을수록 각 프로세스가 자주 CPU를 사용하므로 응답 시간이 짧아집니다. 그러나 문맥 전환이 빈번하게 발생해 오버헤드가 증가합니다.
- 타임 퀀텀이 길면 문맥 전환이 줄어들지만, 응답 시간이 길어져 특정 프로세스가 CPU를 독점하는 상황이 발생할 수 있습니다.
- 적절한 타임 퀀텀 설정이 중요한 이유는 시스템의 성능과 응답 속도에 직접적인 영향을 미치기 때문입니다.
- 선점형 스케줄링:
- 라운드 로빈은 선점형 스케줄링의 일종으로, 타임 퀀텀이 지나면 프로세스가 중단되고 다른 프로세스가 CPU를 사용할 수 있게 됩니다. 따라서 공정한 CPU 분배가 가능합니다.
- 평등한 자원 분배:
- 모든 프로세스가 같은 시간만큼 CPU를 할당받으므로, 여러 사용자나 작업이 동시에 실행되는 환경에서 공평성을 보장합니다.
- 문맥 전환(Context Switch):
- 타임 퀀텀이 끝나면 CPU 제어권을 다른 프로세스로 넘기기 위해 문맥 전환이 발생합니다. 문맥 전환에는 시간이 소요되며, 빈번한 문맥 전환은 오버헤드를 증가시킬 수 있습니다.
라운드 로빈 스케줄링의 장점
- 응답 시간 보장: 각 프로세스가 일정 시간 내에 CPU를 할당받아 실행되므로, 응답 시간이 예측 가능하고, 멀티태스킹 환경에서 사용자에게 좋은 경험을 제공합니다.
- 공평성: 모든 프로세스가 동일한 시간만큼 CPU를 사용할 수 있기 때문에, 자원의 공평한 분배가 가능합니다.
- Starvation(기아 현상) 없음: 우선순위 기반 스케줄링에서 발생할 수 있는 기아 현상이 발생하지 않습니다. 모든 프로세스가 차례로 CPU를 할당받기 때문입니다.
라운드 로빈 스케줄링의 단점
- 오버헤드 증가: 짧은 타임 퀀텀일수록 문맥 전환이 자주 발생하여, 시스템 오버헤드가 증가할 수 있습니다. 이로 인해 성능 저하가 발생할 수 있습니다.
- CPU 버스트가 짧은 프로세스에 불리: 모든 프로세스가 동일한 타임 퀀텀을 적용받기 때문에, CPU 버스트가 짧은 프로세스는 더 긴 프로세스와 같은 대기 시간을 가지며, 비효율적으로 처리될 수 있습니다.
- 적절한 타임 퀀텀 설정의 어려움: 타임 퀀텀을 적절하게 설정하지 않으면 오버헤드가 높아지거나, 응답 속도가 느려질 수 있습니다.
라운드 로빈 스케줄링의 활용
- 멀티태스킹 운영체제에서 여러 프로세스가 동시에 실행되는 것처럼 보이도록 만드는 데 적합합니다.
- 타임 쉐어링 시스템에서 공정하게 CPU 자원을 분배해야 하는 상황에 자주 사용됩니다.
- 인터랙티브 시스템에서 빠른 응답 시간이 요구되는 환경에 적합합니다.
즉 라운드 로빈 스케줄링은 공평성과 응답성을 보장하고, CPU 자원을 효율적으로 분배하는 스케줄링 알고리즘이며 대화형(interactive) 시스템에서 특히 적합한 방식입니다.
-대화형 시스템: 사용자와 시스템 간의 실시간 상호작용을 기반으로 작동하는 컴퓨터 시스템.
SRF(Shortest Remaining Time First, SRTF)
남은 실행 시간이 가장 짧은 프로세스에게 CPU를 우선적으로 할당하는 방식입니다. SRTF는 비선점형 SJF(Shortest Job First)알고리즘의 선점형 버전이라고 할 수 있습니다. 즉, 프로세스가 실행 중이더라도 남은 실행 시간이 더 짧은 다른 프로세스가 도착하면 CPU를 즉시 해당 프로세스에게 넘깁니다.
SRF(SRTF)의 동작 방식
- 프로세스 도착:
- CPU 스케줄러는 대기 중인 모든 프로세스와 현재 실행 중인 프로세스의 남은 실행 시간을 비교합니다.
- 선점:
- 새로운 프로세스가 도착했을 때, 그 프로세스의 남은 실행 시간이 더 짧으면 현재 실행 중인 프로세스를 중단하고, 새로운 프로세스에게 CPU를 할당합니다.
- 프로세스 완료:
- CPU는 해당 프로세스가 완료될 때까지 계속해서 실행하며, 완료 후 다시 대기 큐에서 가장 남은 시간이 짧은 프로세스를 선택하여 실행을 이어갑니다.
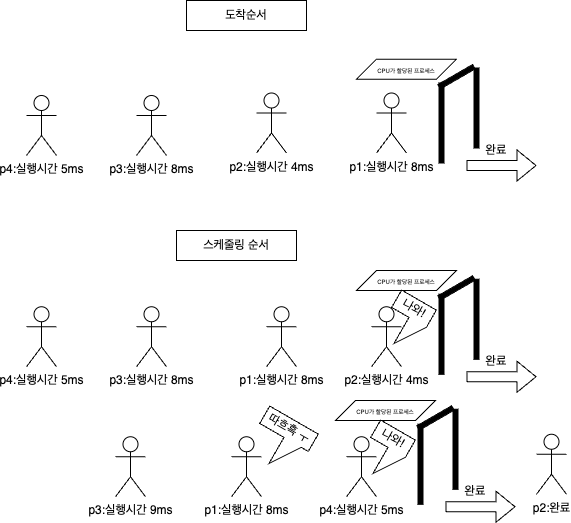
SRF의 예시
프로세스 도착 시간 실행 시간
P1 0 8
P2 1 4
P3 2 9
P4 3 5
SRF 스케줄링 순서
- 0초: P1만 도착했으므로 CPU를 P1에 할당하여 실행합니다.
- 1초: P2가 도착했으며, P2의 실행 시간(4)이 P1의 남은 실행 시간(7)보다 짧으므로 P1을 중단하고 P2를 실행합니다.
- 2초: P3가 도착하지만 P2의 남은 실행 시간(3)이 P3의 실행 시간(9)보다 짧으므로 P2는 계속 실행됩니다.
- 3초: P4가 도착했고, P2의 남은 실행 시간(2)보다 P4의 실행 시간(5)이 길기 때문에 P2는 계속 실행됩니다.
- 5초: P2가 종료된 후, P4가 가장 짧은 남은 실행 시간을 가지므로 P4가 실행됩니다.
- 10초: P4가 종료되면, 남은 실행 시간이 더 짧은 P1이 다시 실행됩니다.
- 17초: P1이 종료된 후, 마지막으로 P3가 실행됩니다.
SRF의 장점
- 대기 시간 최소화: 남은 시간이 짧은 프로세스를 우선 처리하기 때문에 대기 시간과 응답 시간을 최소화할 수 있습니다.
- 공정성: 작업 시간이 짧은 프로세스는 빠르게 처리되고, 오래 걸리는 프로세스는 뒤로 밀릴 수 있지만, 선점형 방식 덕분에 공정하게 CPU를 분배받습니다.
SRF의 단점
- Starvation(기아 현상): 긴 실행 시간을 가진 프로세스는 계속해서 더 짧은 프로세스에게 CPU를 빼앗길 수 있으며, 이로 인해 기아 현상이 발생할 수 있습니다.
- 문맥 전환 오버헤드: 선점형 방식이기 때문에 자주 문맥 전환이 일어나며, 이로 인해 시스템 자원의 낭비와 성능 저하가 발생할 수 있습니다.
SRF와 SJF 비교
SJF는 비선점형 방식이라 한 번 CPU를 할당받으면 해당 프로세스가 끝날 때까지 다른 프로세스가 CPU를 차지 못하지만 SRF는 선점형 방식이라 더 짧은 남은 시간을 가진 프로세스가 도착하면 언제든 CPU를 선점할 수 있다.
다단계 큐(Multilevel Queue)
시스템 내의 프로세스를 여러 개의 큐로 나누어 처리하는 방식입니다. 각 큐는 우선순위가 다르며, 각 큐에서 실행되는 프로세스는 서로 다른 스케줄링 알고리즘을 사용할 수 있습니다. 예를 들어, 하나의 큐는 라운드 로빈(Round Robin) 알고리즘을, 다른 큐는 우선순위 기반 스케줄링을 사용할 수 있습니다.
주요 개념:
- 큐의 분류: 프로세스는 우선순위, 프로세스 종류(시스템 프로세스, 사용자 프로세스 등), 또는 다른 기준에 따라 서로 다른 큐로 분류됩니다.
- 시스템 프로세스는 높은 우선순위 큐에 배치되고, 사용자 프로세스는 낮은 우선순위 큐에 배치될 수 있습니다.
- 큐 간 스케줄링: 각 큐는 독립적으로 스케줄링됩니다. 높은 우선순위 큐의 프로세스가 먼저 실행되며, 그 큐가 비어 있을 때에만 낮은 우선순위 큐의 프로세스가 실행됩니다.
- 큐 내부 스케줄링: 각 큐는 별도의 스케줄링 알고리즘을 사용할 수 있습니다.
- 높은 우선순위 큐에서는 짧은 응답 시간을 보장하기 위해 라운드 로빈 같은 선점형 스케줄링이 사용될 수 있고, 낮은 우선순위 큐에서는 CPU 시간을 더 효율적으로 사용하기 위해 비선점형 스케줄링(FCFS 등)이 사용될 수 있습니다.
장점:
- 효율성: 다단계 큐는 시스템 프로세스와 사용자 프로세스를 명확히 구분하여 중요한 프로세스가 더 빠르게 처리될 수 있습니다.
- 유연성: 큐마다 다른 스케줄링 정책을 적용할 수 있어 다양한 작업에 대응할 수 있습니다.
단점:
- 비탄력성: 한 번 특정 큐에 속한 프로세스는 다른 큐로 이동할 수 없습니다.
- 기아 현상: 낮은 우선순위 큐에 있는 프로세스는 높은 우선순위 큐가 바쁘면 실행되지 못할 가능성이 있습니다.
다단계 큐는 다양한 우선순위의 작업을 효율적으로 처리하기 위한 좋은 방법이지만, 상황에 따라 기아 현상을 방지하기 위한 보완이 필요할 수 있습니다.
'Computer Science' 카테고리의 다른 글
| 자료 구조 - 복잡도 (0) | 2024.09.21 |
|---|---|
| 트랜잭션과 무결성 (0) | 2024.09.14 |
| 메모리(Memory) (6) | 2024.09.01 |
| Stack, Method, Heap 메모리 (0) | 2024.08.11 |
| Overflow, underflow (0) | 2024.08.10 |