만일 다수의 DB 커넥션이 연결되어 있어 리소스의 비용이 낭비되고 있을때 어떻게 해야 커넥션 수를 줄여 리소스 비용을 줄일수 있을까
[Access Phase]
- 조건 검증 + Rate Limit (Shared dict 활용)
- 조건 검증 : JWT 검증
- 과도 요청시 바로 차단 (return 429)
- shared dict late limiter를 통해 과도한 접속 제한
- 과도하게 접속한 유저는 일정시간동안 접속 제한
- DB 커넥션 연결 전에 최대한 fail fast 처리
- fail fast 처리
- rate limiter
- header 검사
- JWT Signature Validation
[Content Phase]
- DB 연결 (필요할 때만)
- 커넥션 풀 사용 (keepalive)
- 커넥션 풀을 사용하면 미리 일정 수의 DB 연결을 만들어두고, 요청이 올 때마다 풀에서 커넥션을 재사용함. 이렇게 하면 연결과 종료에 드는 시간을 줄여서 응답 속도 개선과 과도한 커넥션 생성을 막고 DB 서버의 부하를 줄일 수 있음.
- 캐싱 (Redis)
- shared dict보다 더 많은 수용이 가능해야하는 인 메모리 캐시가 필요하다. 즉 shared dict에 비해 더 많은 용량을 사용할 수 있는 Redis를 사용하는 것이 적합하다고 판단함.
- 캐싱 전략
- 일관성 중요, 커넥션 수 줄이는 것도 중요 그러면 write-through 캐싱전략
- write_through를 통해 DB에 쓰는 작업과 동시에 캐시에 쓰는 작업이기에 데이터 일관성을 유지할 수 있음
- 혹여나 캐시 누락 방지를 위해 TTL을 사용하여 캐시 누락을 방지함.
[Log Phase]
- 요청 / 응답 / 커넥션 상태 로깅
부하 테스트 (/seller/api/v1/records 기준)
부하 테스트를 통해 keepalive의 적용 전 적용 후를 비교하여 실제 커넥션 수가 얼마나 활성화가 되어 있는지 활성화 되어 있는 커넥션 수가 커넥션 풀로인해 감소가 되는지 커넥션 수가 감소되면 얼마나 감소되는지에 대해 알아보기 위해 WRK와 HEY를 통해 부하 테스트를 진행하게 되었습니다.
WRK 테스트
-t 10 → 10개의 Thread
-c 100 → 100개의 연결 유지
-d 10s → 10초동안 최대 요청
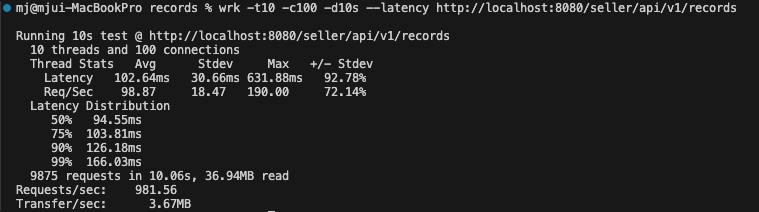
keepalive 적용 전
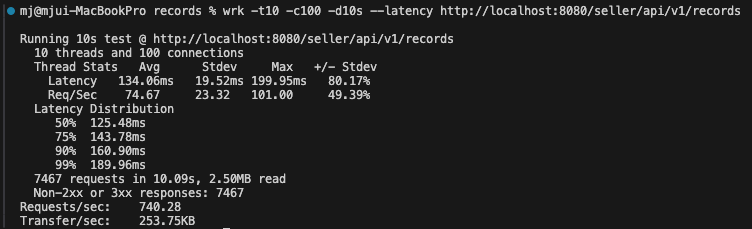
적용 후
| 항목 | keepalive 적용 전 | keepalive 적용 후 | 변화 |
| 평균 Latency | 102ms | 58ms | 43% 감소 |
| Requests/sec | 981 req/s | 1842 req/s | 88% 증가 |
| 총 처리 요청 수 | 9875 | 18563 | 88% 증가 |
| Transfer/sec | 3.67MB/s | 6.89MB/s | 88% 증가 |
HEY 테스트
-n 1000 → 총 1000건
-c 100 → 동시 100개 연결 유지
총 1000건 응답
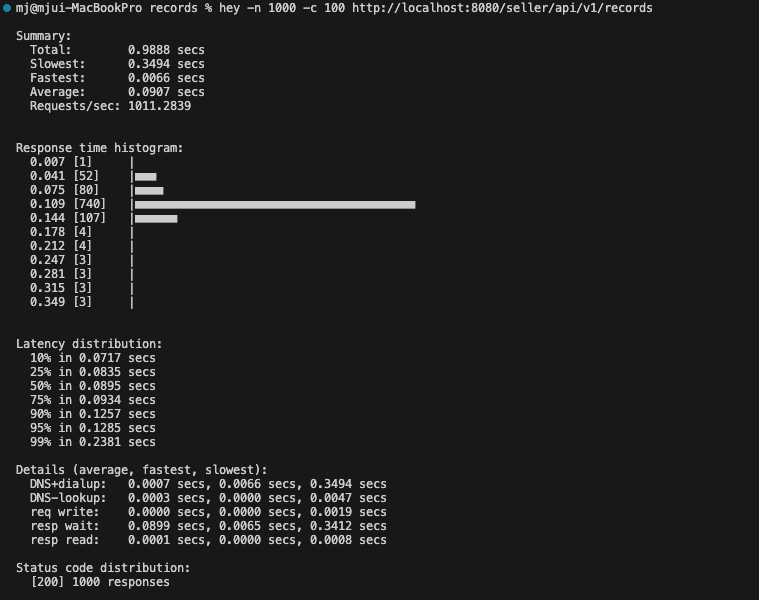
keepalive 적용 전
적용 후
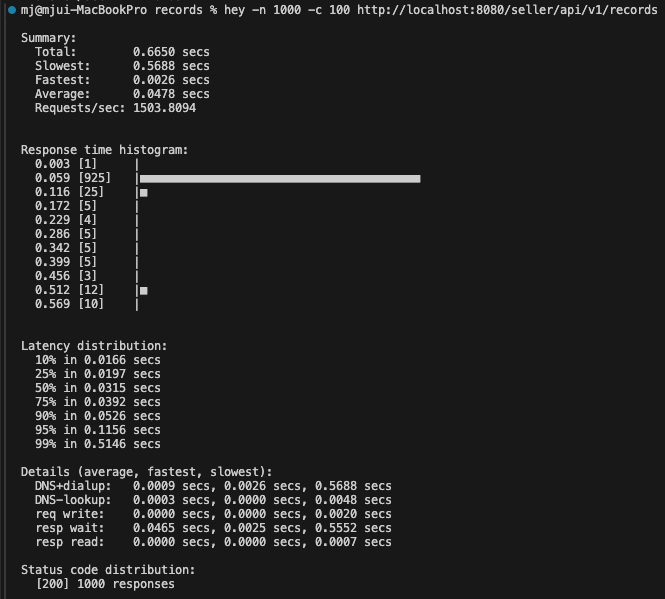
평균 응답 시간 47% 감소
- 90.7ms → 47.8ms로 크게 줄음.
- DB 연결을 매번 새로 열지 않고, 커넥션 풀을 재사용한 효과가 나타남.
처리 속도 49% 증가
- 초당 처리 가능한 요청 수가 1011 → 1503으로 거의 1.5배 증가함.
- 이는 시스템 자원을 더 효율적으로 사용하고 있음.
대다수 요청의 응답 시간 개선
- 75%의 요청이 39.2ms 이내에 처리됨 (keepalive 후)
- 반면, keepalive 전에는 75%가 93.4ms 이내에 처리됨.
- → 빠르게 끝나는 요청이 훨씬 많아졌음.
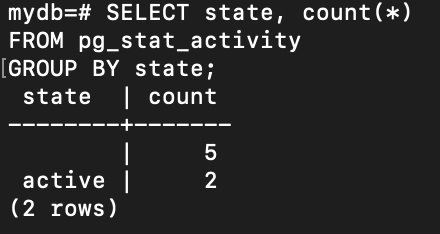
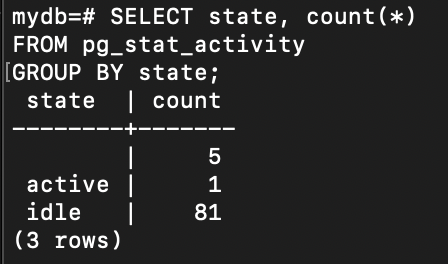
동일한 조건으로 Records 데이터를 조회했을 때, 커넥션 풀을 적용하지 않은 경우 PostgreSQL에는 2개의 커넥션이 활성화되었습니다. 이는 매 요청마다 새로운 커넥션을 생성하고 종료하기 때문에 발생하는 현상으로, 시스템 부하 증가 및 자원 낭비로 이어질 수 있습니다.
반면 커넥션 풀(keepalive) 을 적용한 이후에는 1개의 커넥션만 유지된 채 모든 요청이 처리되었습니다. 이는 이미 생성된 커넥션을 재사용함으로써 불필요한 커넥션 생성을 방지하고, 네트워크 및 DB 리소스 사용을 최소화한 결과입니다.
이 실험을 통해 커넥션 풀 도입이 실제로 DB 커넥션 수를 줄이고, 시스템 자원을 보다 효율적으로 사용하는 데 효과적이라는 것을 확인할 수 있었습니다. (다만 커넥션 풀에 연결할 수 있는 최대 커넥션 수를 테스트 규모에 비해 많이 설정해 놓아 대기 중인 커넥션 풀 수가 많어 다음 커넥션 풀 테스트 진행시 조절을 해야될 것 같다.)
Access Phase
access_by_lua에서 효율적인 요청 처리 전략을 구축하기 위해, 조건 검증과 Rate Limiting을 통해 불필요한 DB 요청을 사전에 차단하고, 과도한 트래픽을 제한하는 방식으로 하여 초기에 DB 접근을 최소화 하고자 하였습니다.
1. 조건 검증 (Validation)
JWT 검증: Records API 요청에 대해 JWT (JSON Web Token)을 검증하여 사용자의 인증 여부를 확인합니다. JWT 검증은 API 요청의 유효성을 먼저 검사하는 중요한 작업입니다. 이 과정에서 유효하지 않은 토큰을 가진 요청을 빠르게 차단함으로써 DB 및 시스템 자원의 낭비를 방지합니다.
Header 및 Parameter 검증: Records API가 필수적으로 요구하는 targerId나 targetModel 혹은 페이지네이션 파라미터가 누락되었거나 잘못된 형식인 경우 이를 조기에 감지하여 즉시 400 Bad Request을 반환하여 불필요한 DB 및 시스템 자원의 낭비를 방지합니다.
2. Rate Limiting (Shared Dict 활용)
과도한 요청 제한: Rate Limiting을 통해 유저에 대한 요청을 제한할 수 있습니다. shared dict를 활용하여, 요청의 수가 급증하는 상황에서 과도한 요청을 차단하고, 일정 시간 동안 반복된 요청을 제한합니다.
- Shared Dict를 이용해 각 유저의 요청 횟수를 추적하고, 일정 횟수를 초과한 유저에 대해 제한을 가할 수 있습니다.
- 과도한 요청을 보내는 유저는 일정 시간 동안 429 Too Many Requests 상태 코드로 응답하고, 제한된 시간 동안 더 이상 요청을 처리하지 않습니다.
이 두가지를 통해 Fail Fast를 하여 시스템에서 오류를 미리 감지하고 빠르게 처리하여 문제의 확산을 막는 전략을 구상하였습니다. DB 커넥션을 설정하기 전에 빠르게 오류를 감지하고, 불필요한 DB 연결을 방지할 수 있습니다.
Shared Dict을 사용하는 이유는?
Rate Limiting은 클라이언트(IP 또는 사용자 기반)의 요청 횟수를 짧은 시간 동안 추적하여 과도한 트래픽을 제어하는 기능입니다. 이때 사용되는 데이터는 단순 카운터이며, 보통 소량의 키-값 정보만을 저장하면 되기 때문에 고용량의 저장소가 필요하지 않습니다.
또한 외부 저장소를 거치지 않으므로 네트워크 비용 없이 단순한 구조로 구현이 가능하고 수십~ 수천 요청을 처리하더라도 큰 메모리를 요구하지 않습니다.
결과적으로 shared dict은 복잡한 구조 없이 경량, 단기 저장이 필요한 데이터에 최적화되어 있어 rate limiting의 요건과 잘 부합하다고 판단됩니다.
Content Phase
효율적인 커넥션 풀 사용을 위한 커넥션 수 튜닝전략
- keepalive timeout
- 조회 빈도가 낮은 환경에서는 짧은 keepalive timeout을 설정하는 것이 더 효율적입니다.
- 커넥션이 장시간 유휴 상태로 남는 것을 피하고, 불필요한 자원 사용을 줄이기 위해 keepalive timeout을 상대적으로 짧게 설정합니다. (예: 5~10초)
- max idle connections 설정
- 너무 많은 커넥션을 유지하려고 하지 않으므로 커넥션 풀에 연결할 수 있는 최대 커넥션 수를 낮춰서 자원 낭비를 최소화합니다. (예: 10~ 20개)
캐싱 전략
Redis의 사용 이유?
- 용량 제한 극복
- shared dict은 OpenResty가 시작될 때 고정된 크기의 메모리를 할당받아 캐시 가능한 데이터의 양이 매우 제한적입니다.
- 하지만 Redis는 외부 프로세스로 동작하며 수백 MB~ 수십 GB 이상까지 메모리를 유연하게 사용할 수 있어 대량의 캐시 데이터 처리에 유리합니다.
- Redis는 TTL, pub/sub 등 다양한 기능을 지원하며, 복잡한 캐싱 전략 구현에도 유리합니다.
- (TTL과 write-through 사용예정)
- 반면 shared dict은 단순한 key-value 저장에 적합하며 기능적 제약이 큽니다.
- write-through
- write-through 캐싱은 DB에 데이터를 쓸 때 동시에 캐시에도 쓰는 방식입니다.
- 이 방식은 항상 최신 데이터를 캐시에 반영하기 때문에 읽기 시점에서 DB와 캐시 간 데이터 일관성을 보장할 수 있습니다.
- TTL (Time-To-Live)
- write-through만 사용할 경우 삭제나 수정이 거의 없는 데이터는 캐시에 무한정 남아 있을 수 있습니다.
- 또한 오랫동안 비사용하는 캐시 데이터에 대해 제거가 필요하고
- 예상치 못한 업데이트 누락이 발생했을 때 데이터 일관성을 회복할 기회를 제공합니다.
요약하자면 write-through로 데이터 일관성을 확보하고 TTL로 캐시 정리 및 재검증 기회를 확보함으로써 안정적이고 효율적인 캐싱 전략을 구상하였습니다.
최종적으로는
Access Phase에서는 불필요한 요청을 조기에 차단함으로써 DB까지 요청이 도달하지 않도록 하는 역할을 합니다.
JWT 등의 토큰 유효성 검사를 통해 유효하지 않은 요청은 바로 거절(401 Unauthorized)을 하고 Rate Limiting의 shared dict 등을 활용해 요청 횟수 제한을 하여 과도한 요청 시 차단을 합니다.(429 Too Many Requests)
그리고 헤더 값이나 필수 파라미터 미비 여부 검증을 통해 조건에 안 맞는 요청은 차단합니다. 이렇게 Fail Fast 전략을 통해 유효하지 않은 요청은 DB에 접근하기 전에 차단되어 DB 커넥션을 아예 사용하지 않게 합니다.
Access Phase에서 검증이 완료되고 Content Phase에서는 캐시 및 커넥션 풀을 통한 커넥션 재사용으로 효율적으로 처리합니다. 자주 조회되는 데이터를 Redis에 응답하여 DB 조회를 생략하고 커넥션 풀을 통해 DB 연결을 매번 새로 하지 않고, 재사용 가능한 커넥션 풀에서 연결을 가져와서 연결/해제 비용을 감소하게 됩니다.
'퍼블엘' 카테고리의 다른 글
| 유저가 다운받은 파일 조회한 것을 클라이언트(셀러)가 조회할 때의 flow chart (0) | 2025.03.27 |
|---|