지금 인프라 구축 과정에서 상당한 난항을 겪고 있는데 원래 fargate-ECS로 사용할 예정이였지만 뜻밖의 kafka 도입으로 인해 EC2-ECS 방식으로 바꿔야 할듯 하다. 일단은 Jenkins는 로컬로 이미 빼놓은 상태라 그대로 사용할듯 싶고, 문제는 기존 jar 파일을 image화 시켜서 레지스트리로 넘겨야 한다.
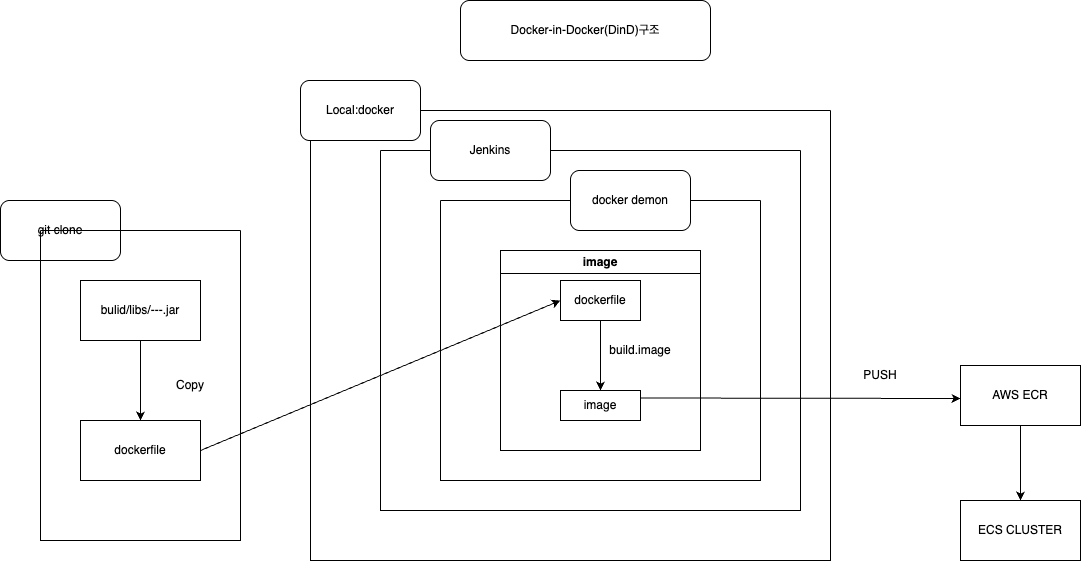
도커 데몬에 접근할려고 하니 접근 권한이 없다고 하여 해당 명령어를 통해 접근 권한을 받았다.
docker exec -u root -it c899fde9ff16 bash
다만 터미널을 통해 젠킨스 서버를 접속할때 가능한 명령어라 디렉토리 구조를 바꿔야 할때 조금의 난항이 있었다. (내가 설정을 못한 것 일수도 있고)
그렇게 하여 도커에 있는 젠킨스 서버에 도커 데몬을 접속을 해야하는데 애초에 젠킨스서버에 root권한이 없어 권한일 다시 주어지고 디렉토리 구조고 내 프로젝트 dockerfile이 있는곳으로 바꿔야 한다.
sudo docker run \
--name jenkins \
-d \
-p 8080:8080 \
-p 50000:50000 \
-v /home/opendocs/jenkins:/var/jenkins_home \
-v /var/run/docker.sock:/var/run/docker.sock \
-u root \
jenkins/jenkins:lts
해당 명령어를 통해 내 dockerfile이 있는 디렉토리에 고정을 시키고 루트 권한을 가지게 하였다.
그 후 dockerfile을 빌드 후 이미지화 해서 ECR로 푸쉬하는것은 성공하였다.

하지만 ECS서버에 deploy를 해야되기 때문에 EC2-ECS 서버를 다시 구축해야한다.
나중에는 로컬에 있는 젠킨스를 클라우드 서버로 옮기는 작업을 할지도...
Karka..를 도입하기에 컴퓨터를 어떤걸로 선택할지 최대 난관이다.
인프라를 구축함에 있어 애매해진 부분이 Karka를 사용해되 MSA가 아닌 Monolithic를 사용하고 elastic cache가 아닌 redis를 사용하니 karka 때문에 비용이 더 들어가는 인스턴스를 선택해야 하니... 고민이 된다.

GPT에게 물어봤을때 karka로 인해 fargate보단 EC2를 선호하고 karka로 인해 redis보다 elastic cache를 추천해주게 된다.

만일 EC2-ECS로 갈시에 인스턴스를 t3, m5, r5로 선택하는데 서버를 원할하게 돌리기 위해서는 메모리는 8GB이상을 요구해야 한다. jenkins를 t2.micro에 돌릴시 메모리가 1GB 밖에 안되어서 가상메모리를 추가해 겨우 돌리는 심정이다. 그리고 알다시피 가상메모리만 추가해서는 여러가지 문제가 생기는데
성능 저하: 디스크는 RAM보다 속도가 느리기 때문에, 실제 메모리 부족으로 인해 스왑 영역을 많이 사용하게 되면 시스템 성능이 크게 떨어질 수 있다. 즉, 디스크 접근 속도가 느려지면서 애플리케이션 반응 속도도 느려진다.
디스크 I/O 증가: 스왑 영역을 사용하게 되면, 디스크의 읽기/쓰기 작업이 잦아져 디스크 I/O가 증가하게 된다. 이로 인해 디스크의 사용 수명이 줄어들거나, 다른 작업의 디스크 접근 속도에 영향을 줄 수 있다.
CPU 사용 증가: 메모리 스왑이 빈번하게 발생하면, CPU는 데이터를 메모리와 디스크 간에 옮기는 작업에 더 많은 시간을 소비하게 되어 전체적인 CPU 사용률이 높아질 수 있다.
응답 시간 지연: 가상 메모리가 실제 메모리보다 많고 스왑이 잦을 경우, 애플리케이션 응답 시간이 느려지며, 특히 사용자 인터페이스를 가진 프로그램에서 딜레이가 심해질 수 있다.
스왑 아웃(Swap Out)과 스왑 인(Swap In): 운영체제는 더 자주 사용되는 데이터를 RAM에 유지하려고 노력하지만, 필요에 따라 스왑을 통해 데이터를 메모리에서 디스크로 이동(스왑 아웃)하거나 다시 가져오게 됩니다(스왑 인). 이 과정이 많아질수록 속도 저하가 발생할 수 이있다.
실제 메모리가 높고 cpu도 메모리에 맞는 성능으로 선택을 해야 한다.
일단 알아본 바로는 각각 필요한 리소스는 이정도 된다.
각 서비스의 리소스 요구 사항
1. Jenkins:
용도: CI/CD 파이프라인 관리
요구 사항: 빌드 및 배포 작업 시 CPU 및 메모리 사용량 증가
추천 사양: 중간 정도의 CPU 및 메모리 (예: 4 vCPU, 16 GB RAM)
2. Kafka:
용도: 실시간 스트리밍 데이터 처리
요구 사항: 높은 CPU 성능, 충분한 메모리, 빠른 디스크 I/O
추천 사양: 고성능 CPU 및 메모리 (예: 4-8 vCPU, 16-32 GB RAM)
3. Redis:
용도: 인메모리 데이터 저장소 및 캐싱
요구 사항: 높은 메모리 용량
추천 사양: 메모리 최적화 인스턴스 (예: 8 vCPU, 32 GB RAM)
4. ELK 스택 (Elasticsearch, Logstash, Kibana):
용도: 로그 수집, 분석 및 시각화
요구 사항: 높은 CPU 및 메모리 사용량
추천 사양: 고성능 CPU 및 충분한 메모리 (예: 4-8 vCPU, 16-32 GB RAM)
5. RDS:
용도: 관계형 데이터베이스 관리
요구 사항: AWS에서 관리되므로 EC2 인스턴스의 리소스 부담은 상대적으로 적음
6. ECR:
용도: 도커 이미지 관리
요구 사항: 리소스 소모가 적음
해당 프로젝트에 권장하는 인스턴스 유형 정리
1. 일반적인 권장 인스턴스 유형: M5 또는 M6 시리즈
m5.xlarge
vCPU: 4
메모리: 16 GB
특징: 균형 잡힌 CPU와 메모리, 다양한 워크로드에 적합
m5.2xlarge
vCPU: 8
메모리: 32 GB
특징: 더 높은 성능과 메모리, 대규모 애플리케이션에 적합
2. 메모리 최적화 인스턴스: R5 시리즈
r5.xlarge
vCPU: 4
메모리: 32 GB
특징: 메모리 집약적인 애플리케이션에 적합
r5.2xlarge
vCPU: 8
메모리: 64 GB
특징: 대규모 메모리 요구 사항을 가진 애플리케이션에 적합
스케일링:
초기에는 소규모 인스턴스로 시작하되, 트래픽과 리소스 사용량이 증가함에 따라 인스턴스 유형을 확장하거나, 여러 인스턴스를 사용하여 부하를 분산시키는 방법을 고려해야한다
AWS Auto Scaling 그룹을 설정하여 트래픽 변화에 따라 자동으로 인스턴스를 추가하거나 제거도 고려
비용 효율성:
필요 이상의 인스턴스를 선택하면 비용이 증가할 수 있으므로, 실제 사용량을 모니터링하면서 적절하게 조정도 필요
예약 인스턴스나 스팟 인스턴스를 사용하여 비용을 절감
네트워크 성능:
Kafka와 ELK 스택은 네트워크 성능이 중요한 경우가 많으므로, 인스턴스 유형 선택 시 네트워크 성능도 고려
M5와 R5 시리즈는 일반적으로 높은 네트워크 성능을 제공
결론은?
초기에는 m5.xlarge (4 vCPU, 16 GB RAM) 인스턴스로 시작하여 리소스 사용량을 모니터링한 후
필요에 따라 m5.2xlarge (8 vCPU, 32 GB RAM)로 업그레이드
만약 Redis나 ELK 스택이 매우 메모리를 많이 사용하는 경우, r5.xlarge (4 vCPU, 32 GB RAM) 또는 r5.2xlarge (8 vCPU, 64 GB RAM)와 같은 메모리 최적화 인스턴스를 사용.
처음은 일단 m5.xlarge 결정!
'우리 지금 만나' 카테고리의 다른 글
| 소모임 단건 조회에 RedisLimiter를 적용 후 Jmeter 테스트-(6)(우리 지금 만나) (0) | 2024.10.30 |
|---|---|
| 소모임 다건 목록 Redis 적용 후 Jmeter 테스트 정리-(5)(우리 지금 만나) (0) | 2024.10.30 |
| 인프라 설계 -(3)(우리 지금 만나) (8) | 2024.10.23 |
| AWS S3 첨부파일-(2)(우리 지금 만나) (2) | 2024.10.23 |
| 프로젝트 초안 작성-(1)(우리 지금 만나) (8) | 2024.10.21 |